Introduction
The oracle alert.log and listener.log contain useful information to provide answer to questions like:
- When did the Instance start?
- When has the Instance been shutdown?
- When did ORA- occur? With which code?
- Which IP client did connect to the Instance? With which user?
- How did it connect? Through a service? Through the SID?
- Which program has been used to connect?
- A connection storm occurred, what is the source of it?
What about having all this information centralized? What about having the possibility to gather, format, search, analyze and visualize this information in real time?
To achieve this, let’s use the ELK stack:
- Logstash to collect the information the way we want to.
- Elasticsearch as an analytics engine.
- Kibana to visualize the data.
Installation
The installation is very simple.
- Install elasticsearch
[root@elk ~]# wget https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.2.1/elasticsearch-2.2.1.rpm
[root@elk ~]# yum localinstall elasticsearch-2.2.1.rpm
- Edit the configuration file to mention on which host it has been installed (namely elk in my case):
[root@elk ~]# grep network.host /etc/elasticsearch/elasticsearch.yml
network.host: elk
- Start elasticsearch:
[root@elk ~]# /etc/init.d/elasticsearch start
Starting elasticsearch: [ OK ]
- Install Kibana:
[root@elk ~]# wget https://download.elastic.co/kibana/kibana/kibana-4.4.2-linux-x64.tar.gz
[root@elk ~]# tar -xf kibana-4.4.2-linux-x64.tar.gz --directory /opt
[root@elk ~]# mv /opt/kibana-4.4.2-linux-x64 /opt/kibana
- Edit the configuration file so that the url is updated accordingly:
[root@elk ~]# grep elasticsearch.url /opt/kibana/config/kibana.yml
elasticsearch.url: "http://elk:9200"
- Start Kibana:
[root@elk ~]# /opt/kibana/bin/kibana
- Install logstash on the oracle host (namely dprima in my case):
[root@dprima ~]# wget https://download.elastic.co/logstash/logstash/packages/centos/logstash-2.2.2-1.noarch.rpm
[root@dprima ~]# yum localinstall logstash-2.2.2-1.noarch.rpm
Configure logstash to push and format the alert.log to elasticsearch the way we want to
So that:
- The @timestamp field is reflecting the timestamp at which the log entry was created (rather than when logstash read the log entry).
- It traps ORA- entries and creates a field ORA- when it occurs.
- It traps the start of the Instance (and fill a field oradb_status accordingly).
- It traps the shutdown of the Instance (and fill a field oradb_status accordingly).
- It traps the fact that the Instance is running (and fill a field oradb_status accordingly).
New fields are being created so that we can analyze/visualize them later on with Kibana.
- To trap and format this information, let’s create an alert_log.conf configuration file that looks like (the filter part contains the important stuff):
input {
file {
path => "/u01/app/oracle/diag/rdbms/pbdt/PBDT/trace/alert_PBDT.log"
}
}
filter {
# Join lines based on the time
multiline {
pattern => "%{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{YEAR}"
negate => true
what => "previous"
}
# Create new field: oradb_status: starting,running,shutdown
if [message] =~ /Starting ORACLE instance/ {
mutate {
add_field => [ "oradb_status", "starting" ]
}
} else if [message] =~ /Instance shutdown complete/ {
mutate {
add_field => [ "oradb_status", "shutdown" ]
}
} else {
mutate {
add_field => [ "oradb_status", "running" ]
}
}
# Search for ORA- and create field if match
if [message] =~ /ORA-/ {
grok {
match => [ "message","(?<ORA->ORA-[0-9]*)" ]
}
}
# Extract the date and the rest from the message
grok {
match => [ "message","%{DAY:day} %{MONTH:month} %{MONTHDAY:monthday} %{TIME:time} %{YEAR:year}(?<log_message>.*$)" ]
}
mutate {
add_field => {
"timestamp" => "%{year} %{month} %{monthday} %{time}"
}
}
# replace the timestamp by the one coming from the alert.log
date {
locale => "en"
match => [ "timestamp" , "yyyy MMM dd HH:mm:ss" ]
}
# replace the message (remove the date)
mutate { replace => [ "message", "%{log_message}" ] }
mutate {
remove_field => [ "time" ,"month","monthday","year","timestamp","day","log_message"]
}
}
output {
elasticsearch {
hosts => ["elk:9200"]
index => "oracle-%{+YYYY.MM.dd}"
}
}
- Start logstash with this configuration file:
[root@dprima ~]# /opt/logstash/bin/logstash -f /etc/logstash/conf.d/alert_log.conf
- So that for example an entry in the alert.log file like:
Sat Mar 26 08:30:26 2016
ORA-1653: unable to extend table SYS.BDT by 8 in tablespace BDT
will be formatted and send to elasticsearch that way:
{
"message" => "\nORA-1653: unable to extend table SYS.BDT by 8 in tablespace BDT ",
"@version" => "1",
"@timestamp" => "2016-03-26T08:30:26.000Z",
"path" => "/u01/app/oracle/diag/rdbms/pbdt/PBDT/trace/alert_PBDT.log",
"host" => "Dprima",
"tags" => [
[0] "multiline"
],
"oradb_status" => "running",
"ORA-" => "ORA-1653"
}
Configure logstash to push and format the listener.log to elasticsearch the way we want to
So that:
- The @timestamp field is reflecting the timestamp at which the log entry was created (rather than when logstash read the log entry).
- It traps the connections and records the program into a dedicated field program.
- It traps the connections and records the user into a dedicated field user.
- It traps the connections and records the ip of the client into a dedicated field ip_client.
- It traps the connections and records the destination into a dedicated field dest.
- It traps the connections and records the destination type (SID or service_name) into a dedicated field dest_type.
- It traps the command (stop, status, reload) and records it into a dedicated field command.
New fields are being created so that we can analyze/visualize them later on with Kibana.
- To trap and format this information, let’s create a lsnr_log.conf configuration file that looks like (the filter part contains the important stuff):
input {
file {
path => "/u01/app/oracle/diag/tnslsnr/Dprima/listener/trace/listener.log"
}
}
filter {
if [message] =~ /(?i)CONNECT_DATA/ {
# Extract the date and the rest from the message
grok {
match => [ "message","(?<the_date>.*%{TIME})(?<lsnr_message>.*$)" ]
}
# Extract COMMAND (like status,reload,stop) and add a field
if [message] =~ /(?i)COMMAND=/ {
grok {
match => [ "lsnr_message","^.*(?i)COMMAND=(?<command>.*?)).*$" ]
}
} else {
# Extract useful Info (USER,PROGRAM,IPCLIENT) and add fields
grok {
match => [ "lsnr_message","^.*PROGRAM=(?<program>.*?)).*USER=(?<user>.*?)).*ADDRESS.*HOST=(?<ip_client>%{IP}).*$" ]
}
}
# replace the timestamp by the one coming from the listener.log
date {
locale => "en"
match => [ "the_date" , "dd-MMM-yyyy HH:mm:ss" ]
}
# replace the message (remove the date)
mutate { replace => [ "message", "%{lsnr_message}" ] }
# remove temporary fields
mutate { remove_field => [ "the_date","lsnr_message"] }
# search for SID or SERVICE_NAME, collect dest and add dest type
if [message] =~ /(?i)SID=/ {
grok { match => [ "message","^.*(?i)SID=(?<dest>.*?)).*$" ] }
mutate { add_field => [ "dest_type", "SID" ] }
}
if [message] =~ /(?i)SERVICE_NAME=/ {
grok { match => [ "message","^.*(?i)SERVICE_NAME=(?<dest>.*?)).*$" ] }
mutate { add_field => [ "dest_type", "SERVICE" ] }
}
} else {
drop {}
}
}
output {
elasticsearch {
hosts => ["elk:9200"]
index => "oracle-%{+YYYY.MM.dd}"
}
}
- Start logstash with this configuration file:
[root@Dprima conf.d]# /opt/logstash/bin/logstash -f /etc/logstash/conf.d/lsnr_log.conf
- So that for example an entry in the listener.log file like:
26-MAR-2016 08:34:57 * (CONNECT_DATA=(SID=PBDT)(CID=(PROGRAM=SQL Developer)(HOST=__jdbc__)(USER=bdt))) * (ADDRESS=(PROTOCOL=tcp)(HOST=192.168.56.1)(PORT=50379)) * establish * PBDT * 0
will be formatted and send to elasticsearch that way:
{
"message" => " * (CONNECT_DATA=(SID=PBDT)(CID=(PROGRAM=SQL Developer)(HOST=__jdbc__)(USER=bdt))) * (ADDRESS=(PROTOCOL=tcp)(HOST=192.168.56.1)(PORT=50380)) * establish * PBDT * 0",
"@version" => "1",
"@timestamp" => "2016-03-26T08:34:57.000Z",
"path" => "/u01/app/oracle/diag/tnslsnr/Dprima/listener/trace/listener.log",
"host" => "Dprima",
"program" => "SQL Developer",
"user" => "bdt",
"ip_client" => "192.168.56.1",
"dest" => "PBDT",
"dest_type" => "SID"
}
Analyze and Visualize the data with Kibana
- Connect to the elk host, (http://elk:5601) and create an index pattern (Pic 1):
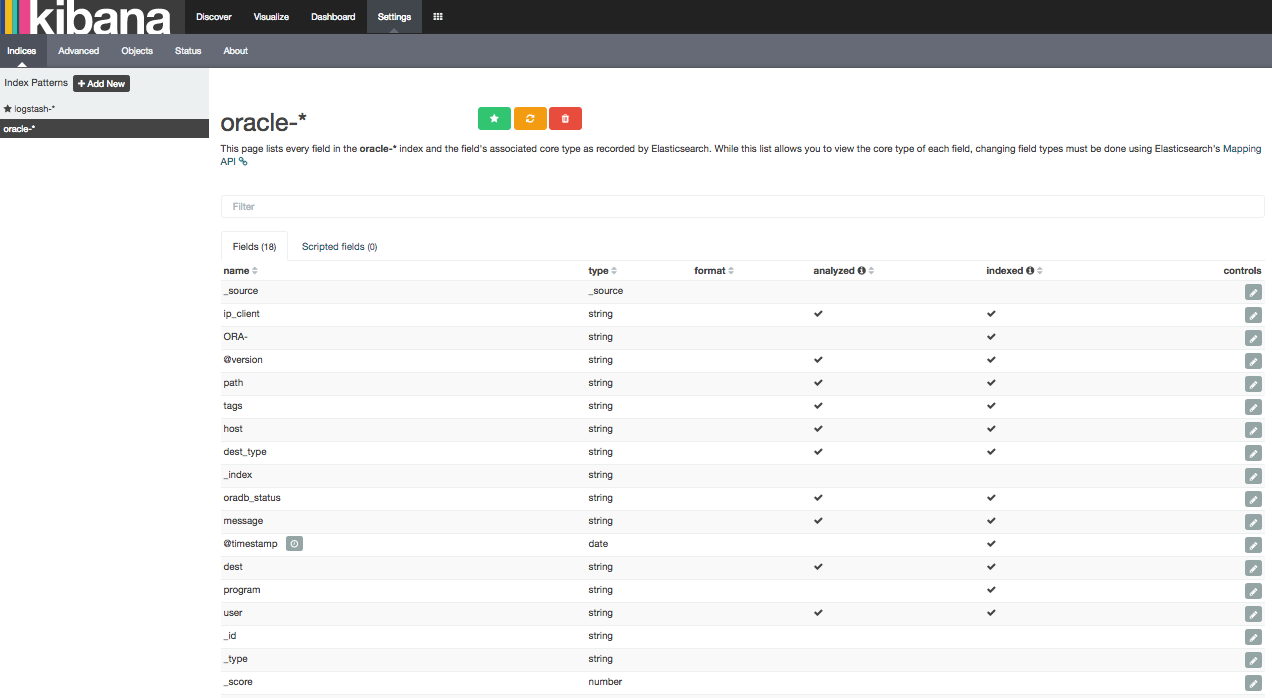
- Check that all our custom fields have been indexed (this is the default behaviour) (Pic 2):
so that we can now visualize them.
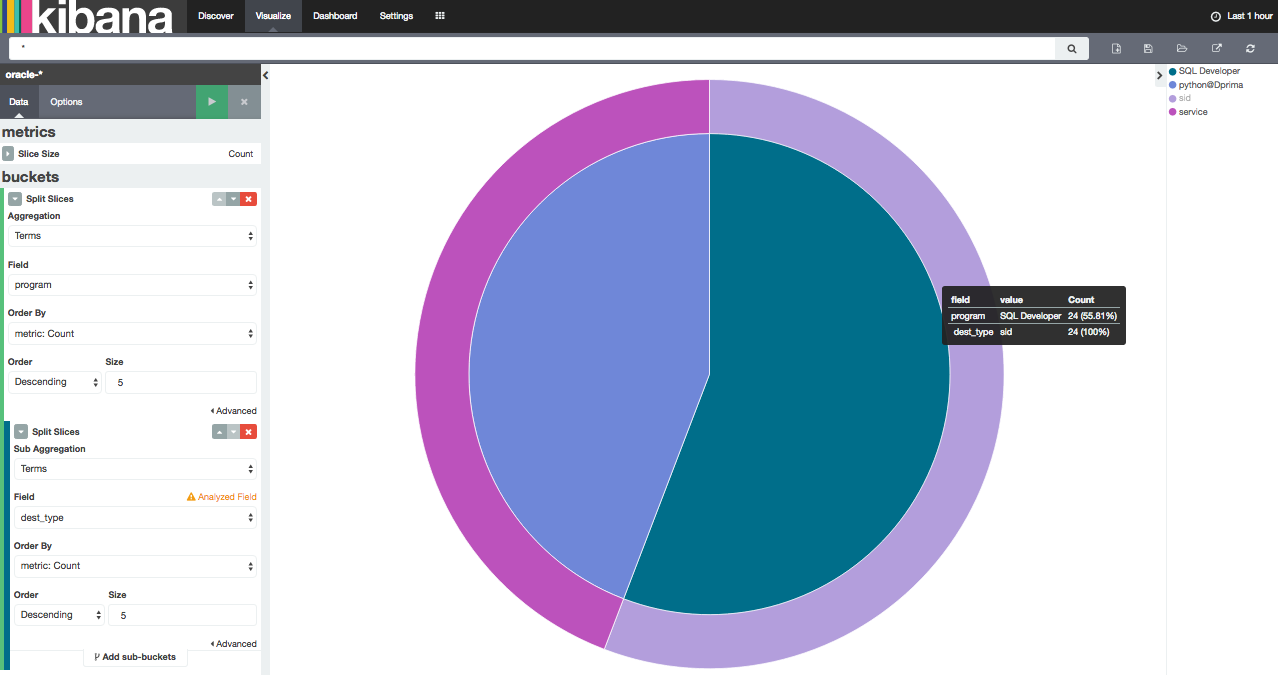
- Example 1: thanks to the listener.log data, let’s graph the connection repartition to our databases by program and by dest_type (Pic 3):
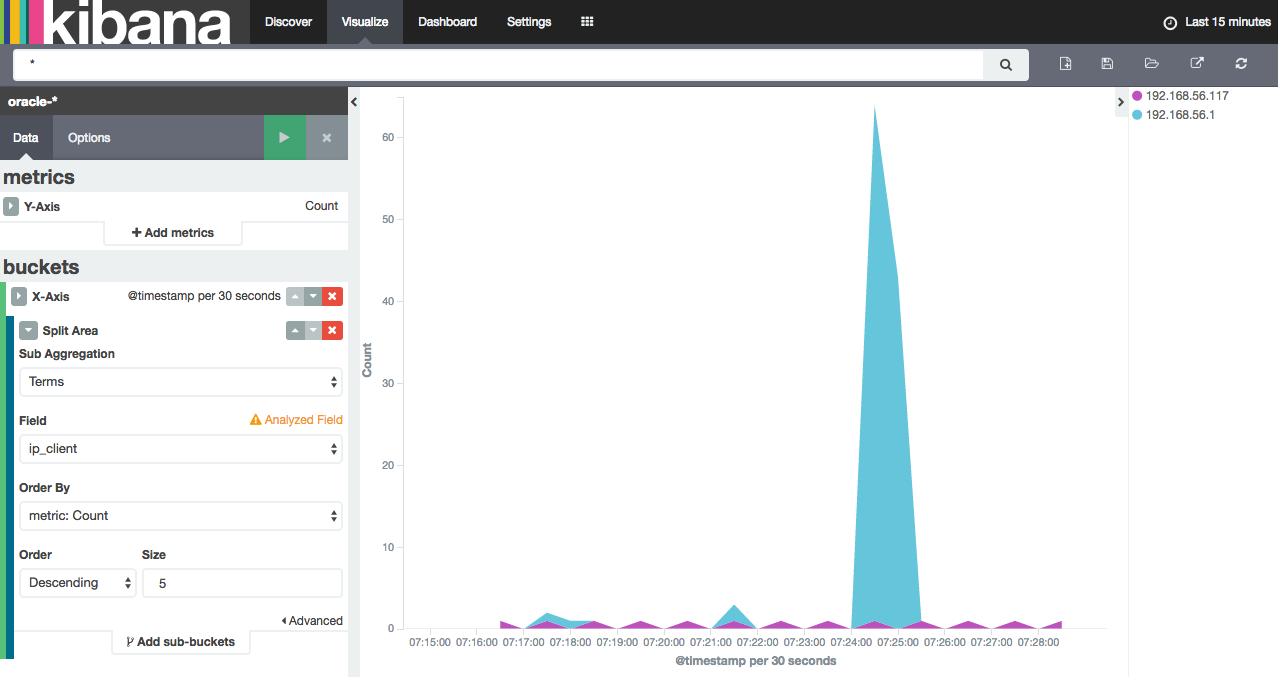
- Example 2: thanks to the listener.log data, visualize when a connection “storm” occurred and where it came from (ip_client field):
Remarks
- As you can see (into the Pic 2) the index on the program field has not been analyzed. By doing so, a connection to the database with “SQL Developer” will be stored in the index as “SQL Developer” and this is what we want. While an analyzed index would have stored 2 distincts values (“SQL” and “Developer”). The same apply for the ORA- field: ORA-1653 would store ORA and 1653 if analyzed (This is why it is specified as not analyzed as well). You can find more details here.
- To get the indexes on the program and ORA- fields not analyzed, a template has been created that way:
curl -XDELETE elk:9200/oracle*
curl -XPUT elk:9200/_template/oracle_template -d ' {
"template" : "oracle*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"oracle" : {
"properties" : {
"program" : {"type" : "string", "index": "not_analyzed" },
"ORA-" : {"type" : "string", "index": "not_analyzed" }
}
}
}
}'
- The configuration files are using grok. You can find more information about it here.
- You can find much more informations about the ELK stack (and another way to use it) into this blog post from Robin Moffatt
- All you need to do to visualize the data is to extract the fields of interest from the log files and be sure an index is created on each field you want to visualize.
- All this information coming from all the machines of a datacenter being centralized into a single place is a gold mine from my point of view.
Conclusion
Thanks to the ELK stack you can gather, centralize, analyze and visualize the content of the alert.log and listener.log files for your whole datacenter the way you want to. This information is a gold mine and the imagination is the only limit.