Suppose that you decided to put the ASM preferred feature in place because you observed that the read latency is too high on the farthest disk array (You can find how you can lead to this conclusion with the use case 3 into this post).
So, you want to enable the ASM preferred read feature so that:
- The +ASM1 instance “prefers” to read from the “WIN” failgroup.
- The +ASM2 instance “prefers” to read from the “JMO” failgroup.
But doing so may have an impact on the number of read IOPS and the throughput repartition per host/disk array because:
- The “previous” ASM1 to JMO reads will now be done on the “WIN” array.
- The “previous” ASM2 to WIN reads will now be done on the “JMO” array.
Of course, the total number of read operations and throughput will not change, but the repartition across the failgroup (disk array) may change with the ASM preferred read feature in place.
Question:
- Is the architecture able to deal with this new read repartition?
To answer this question I will:
- Collect the ASM metrics during a certain amount of time (without the ASM preferred read in place) and produce a csv file as described here.
- Visualize the ASM metrics with Tableau and simulate the impact of the preferred read feature on the read IOPS and the throughput repartition.
Once the csv file is ready (means you collected a representative workload), let’s check what the current workload is (Without the ASM preferred read in place).
For the Kby Read/s measure:
We can visualize it that way with Tableau (I keep the “columns”, “rows” and “marks” shelf into the print screen so that you can reproduce).
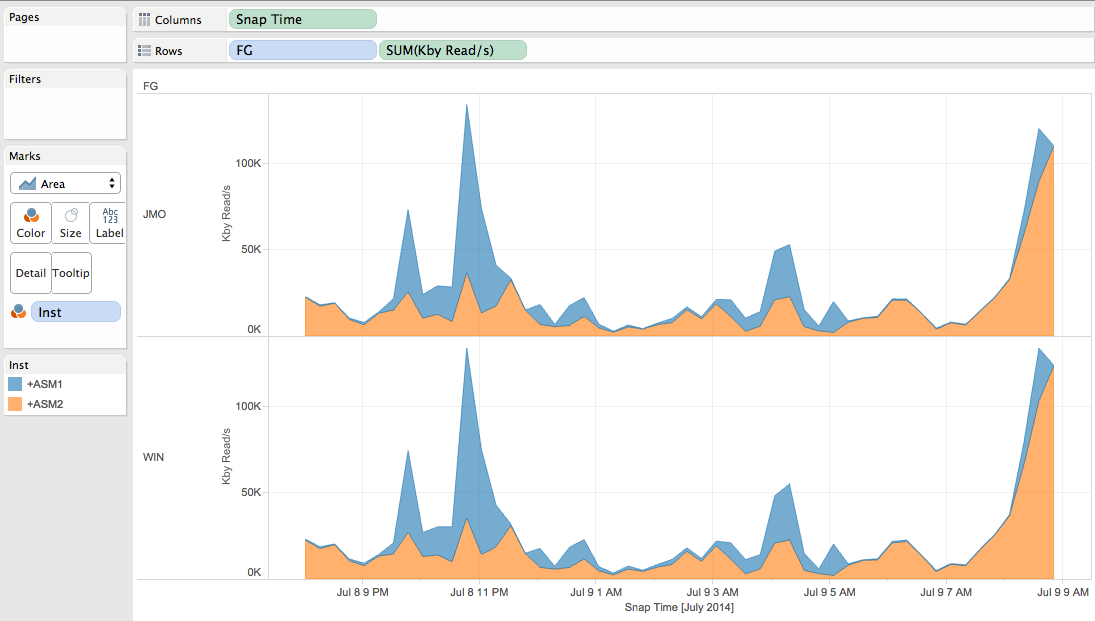
For the Reads/s measure:
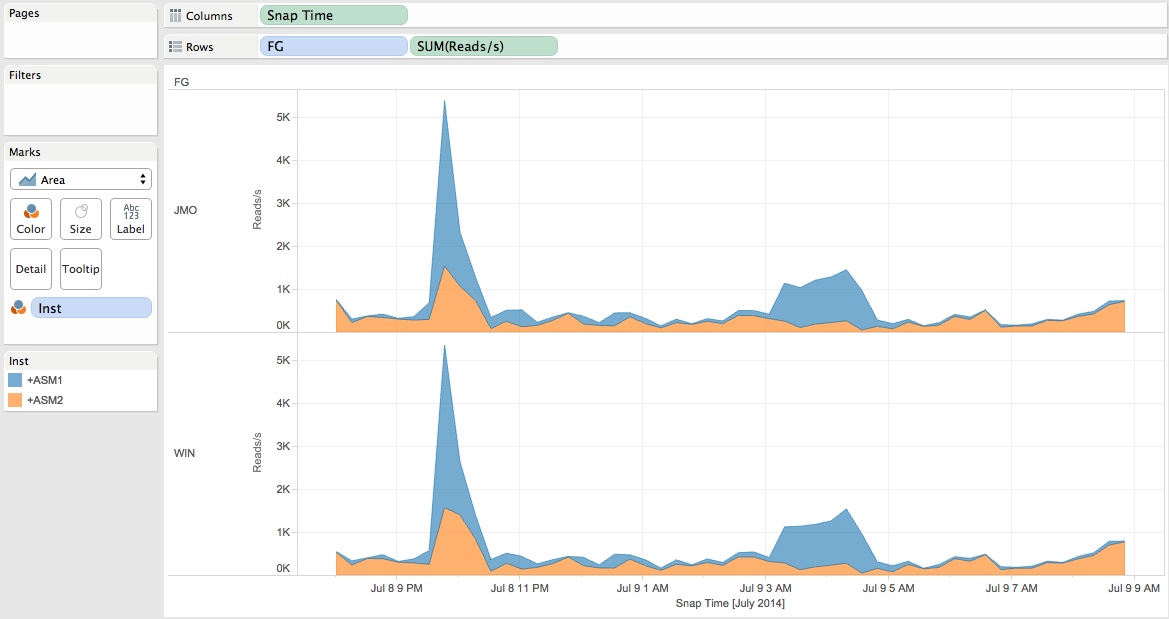
Now, what If we implement the ASM preferred feature? What would be the impact on the read IOPS and the throughput repartition?
To simulate and visualize the impact, let’s create this “New FG for Read operations” calculated field:
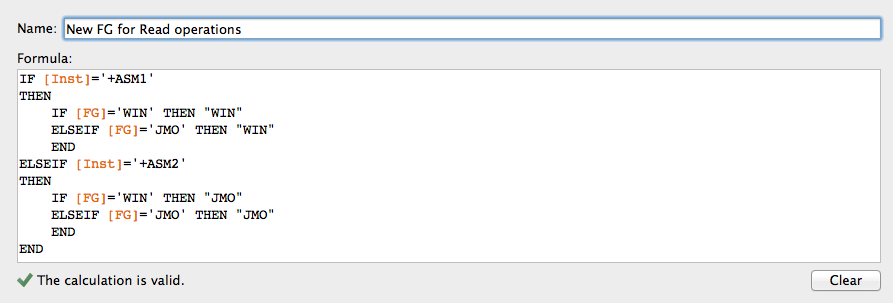
Basically it simulates the ASM preferred Read in place by assigning the failgroup per ASM instances.
Now, let’s simulate and visualize the impact of the ASM preferred read feature (should it be implemented) using the same csv file and this calculated field as dimension.
For the Kby Read/s measure:
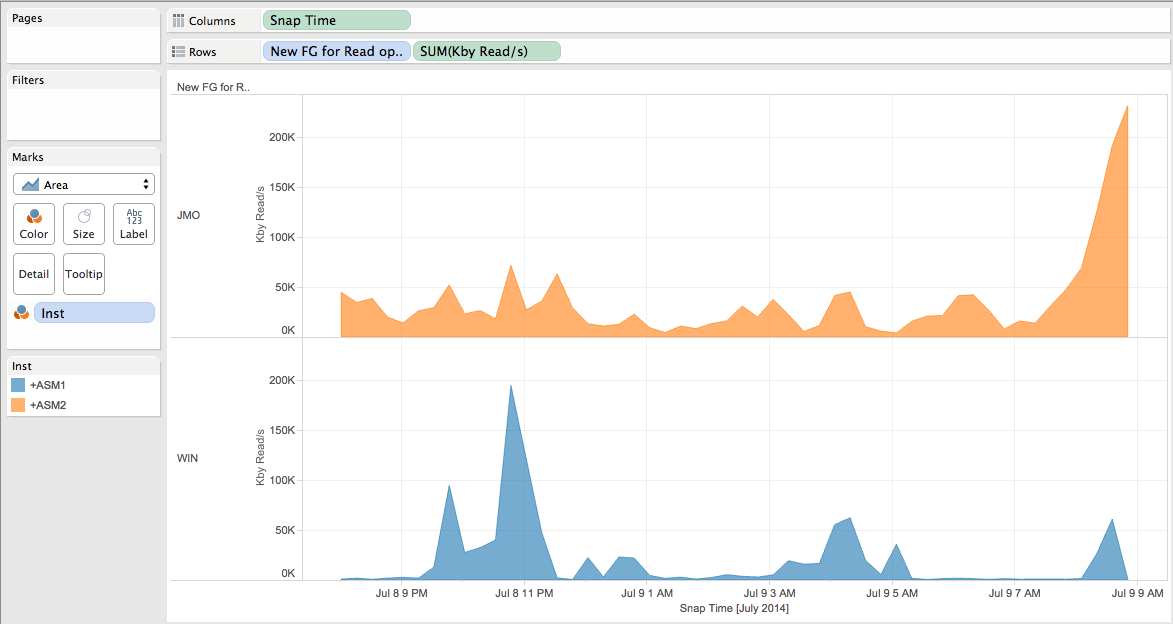
Note that the throughput repartition would not be the same and that the peak are higher (> 200 Mo/s compare to about 130 Mo/s without the ASM preferred read).
For the Reads/s measure:
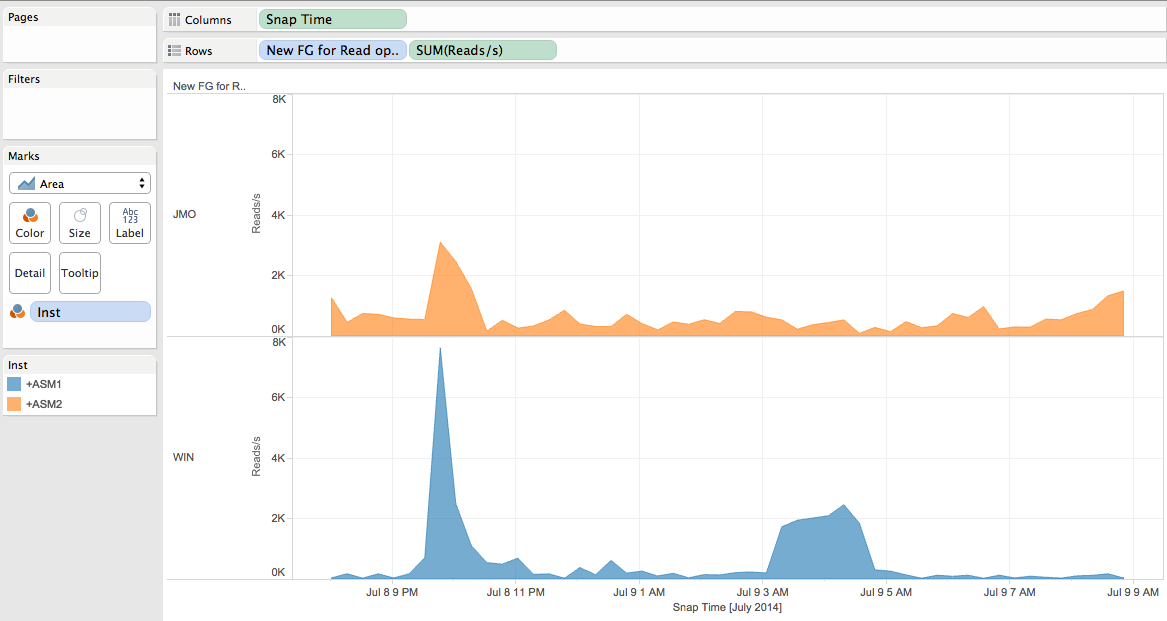
Note that the read IOPS repartition would not be the same and that the peak on the WIN failgroup is higher (about 8000 Reads/s compare to about 5000 Reads/s without the ASM preferred read).
Now you can check (with your Systems and Storage administrators) if your current architecture would be able to deal with this new repartition.
Remarks:
- ASM is not performing any reads for the database, it records metrics for the database instances that it is servicing.
- I would not suggest to use the Flex ASM feature with the ASM preferred read because the preferred read feature is broken with Flex ASM 12c (12.1) in place.
Conclusion:
We have been able to simulate and visualize the impact of the ASM preferred read feature on the read IOPS and the throughput repartition without actually implementing it.