Introduction
TOAST stands for “The Oversized-Attribute Storage Technique” and allows to broke up large fields value into multiple physical rows (see the PostgreSQL documentation for more details).
The goal of this post is to provide a way to retrieve toast’s information from the user table tuples or from the toast index without querying the toast directly.
We will be able to link the user table tuples to the toast pages by using user table tuples and toast index data (not querying the toast at all).
Build the playground
Create a table with a TOAST-able field:
toasted=# CREATE TABLE bdttab (id int,message text,age int);
CREATE TABLE
toasted=# \d+ bdttab
Table "public.bdttab"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
---------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
message | text | | | | extended | |
age | integer | | | | plain | |
Access method: heap
Insert 10 rows:
toasted=# INSERT INTO bdttab
SELECT 1,(SELECT
string_agg(chr(floor(random() * 26)::int + 65), '')
FROM generate_series(1,10000)),6
FROM generate_series(1,10);
INSERT 0 10
check the toast and toast index names:
toasted=# select r.relname,t.relname as toast,i.relname as toast_index from pg_class r, pg_class i, pg_index d, pg_class t where r.relname = 'bdttab' and d.indrelid = r.reltoastrelid and i.oid = d.indexrelid and t.oid = r.reltoastrelid;
relname | toast | toast_index
---------+-----------------+-----------------------
bdttab | pg_toast_192881 | pg_toast_192881_index
(1 row)
Retrieve the chunk_id for each tuple directly from the user table
The chunk_id is part of the tuple’s data as explained in this slide (coming from this presentation):
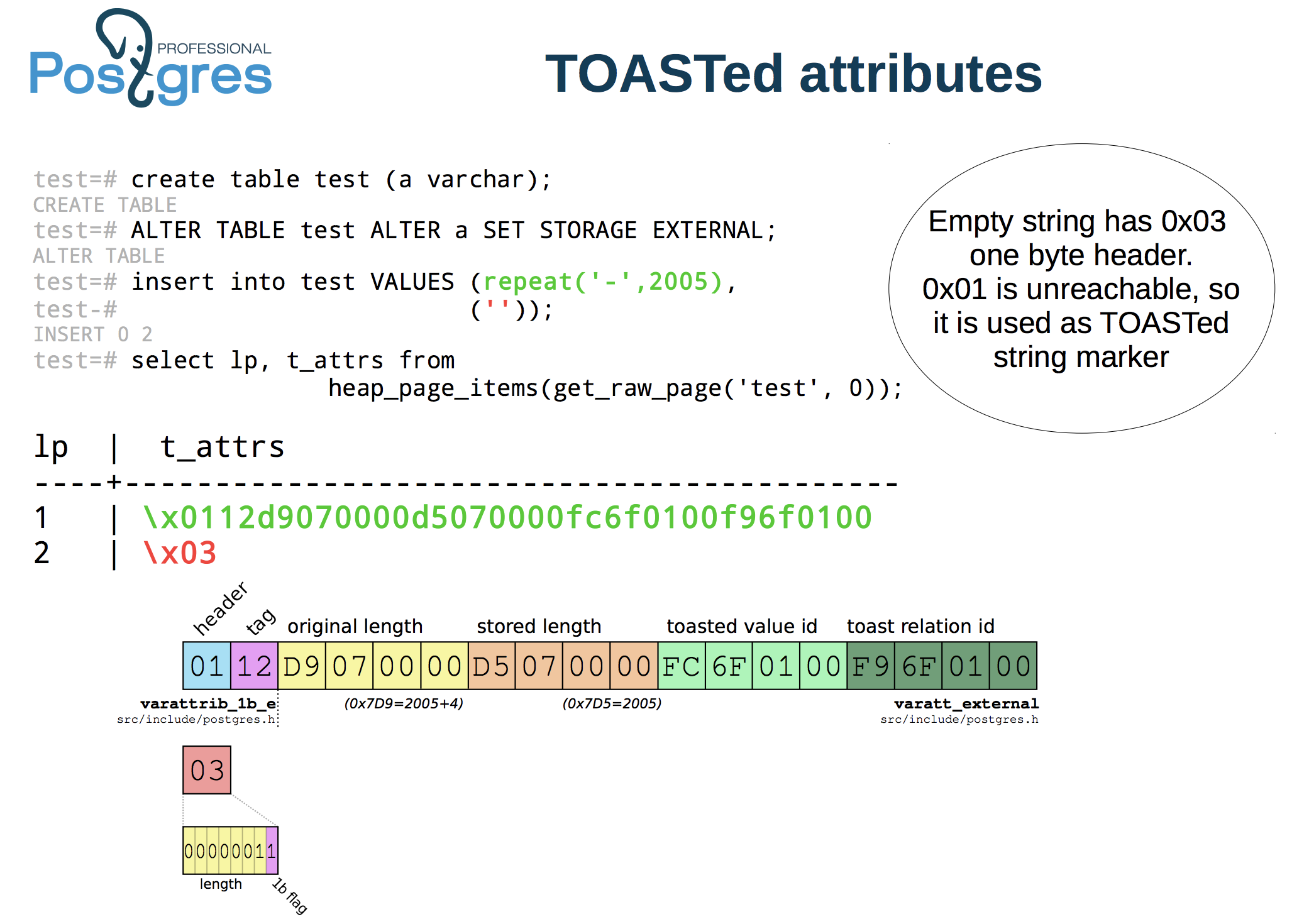
Note that the toast relation id is also part of the tuple data.
As you can see from the slide we can get the information with pageinspect, so let’s use it to build a query to retrieve the chunk_id and the toast relation id from the tuples:
create the extension:
toasted=# create extension pageinspect;
CREATE EXTENSION
and query the user table to get the information:
toasted=# select
page_item_attrs.t_ctid,
page_item_attrs.t_attrs[2],
substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-7,4)::text,3) as substr_for_chunk_id,
('x'||regexp_replace(substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-7,4)::text,3),'(\w\w)(\w\w)(\w\w)(\w\w)','\4\3\2\1'))::bit(32)::int as chunk_id,
substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-3,4)::text,3) as substr_for_toast_relid,
('x'||regexp_replace(substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-3,4)::text,3),'(\w\w)(\w\w)(\w\w)(\w\w)','\4\3\2\1'))::bit(32)::int as toast_relid
FROM
generate_series(0, pg_relation_size('bdttab'::regclass::text) / 8192 - 1) blkno ,
heap_page_item_attrs(get_raw_page('bdttab', blkno::int), 'bdttab'::regclass) as page_item_attrs
where
substr(page_item_attrs.t_attrs[2]::text,3,2)='01';
t_ctid | t_attrs | substr_for_chunk_id | chunk_id | substr_for_toast_relid | toast_relid
--------+----------------------------------------+---------------------+----------+------------------------+-------------
(0,1) | \x0112142700001027000077f1020074f10200 | 77f10200 | 192887 | 74f10200 | 192884
(0,2) | \x0112142700001027000078f1020074f10200 | 78f10200 | 192888 | 74f10200 | 192884
(0,3) | \x0112142700001027000079f1020074f10200 | 79f10200 | 192889 | 74f10200 | 192884
(0,4) | \x011214270000102700007af1020074f10200 | 7af10200 | 192890 | 74f10200 | 192884
(0,5) | \x011214270000102700007bf1020074f10200 | 7bf10200 | 192891 | 74f10200 | 192884
(0,6) | \x011214270000102700007cf1020074f10200 | 7cf10200 | 192892 | 74f10200 | 192884
(0,7) | \x011214270000102700007df1020074f10200 | 7df10200 | 192893 | 74f10200 | 192884
(0,8) | \x011214270000102700007ef1020074f10200 | 7ef10200 | 192894 | 74f10200 | 192884
(0,9) | \x011214270000102700007ff1020074f10200 | 7ff10200 | 192895 | 74f10200 | 192884
(0,10) | \x0112142700001027000080f1020074f10200 | 80f10200 | 192896 | 74f10200 | 192884
(10 rows)
as you can see we are able to get the chunk_id and the toast relation id from the tuples.
Let’s verify that those values make sense, first checking the toast relation id:
toasted=# select relname from pg_class where oid=192884;
relname
-----------------
pg_toast_192881
(1 row)
and then checking the chunk_ids from the toast itself:
toasted=# select distinct(chunk_id) from pg_toast.pg_toast_192881;
chunk_id
----------
192894
192895
192889
192888
192893
192892
192896
192891
192887
192890
(10 rows)
The values match the ones we got directly from the user table tuples.
Retrieve the chunk_id and chunk_seq directly from the toast index
The toast index contains those information, so let’s query it too:
toasted=# select
page_items.ctid,
page_items.data,
('x'||regexp_replace(substr(page_items.data,1,11),'(\w\w) (\w\w) (\w\w) (\w\w)','\4\3\2\1'))::bit(32)::int as chunk_id,
('x'||regexp_replace(substr(page_items.data,13,23),'(\w\w) (\w\w) (\w\w) (\w\w)','\4\3\2\1'))::bit(32)::int as chunk_seq
FROM
generate_series(1, pg_relation_size('pg_toast.pg_toast_192881_index'::regclass::text) / 8192 - 1) blkno ,
bt_page_items('pg_toast.pg_toast_192881_index', blkno::int) as page_items;
ctid | data | chunk_id | chunk_seq
--------+-------------------------+----------+-----------
(0,1) | 77 f1 02 00 00 00 00 00 | 192887 | 0
(0,2) | 77 f1 02 00 01 00 00 00 | 192887 | 1
(0,3) | 77 f1 02 00 02 00 00 00 | 192887 | 2
(0,4) | 77 f1 02 00 03 00 00 00 | 192887 | 3
(1,1) | 77 f1 02 00 04 00 00 00 | 192887 | 4
(1,2) | 77 f1 02 00 05 00 00 00 | 192887 | 5
(1,3) | 78 f1 02 00 00 00 00 00 | 192888 | 0
(1,4) | 78 f1 02 00 01 00 00 00 | 192888 | 1
(2,1) | 78 f1 02 00 02 00 00 00 | 192888 | 2
(2,2) | 78 f1 02 00 03 00 00 00 | 192888 | 3
(2,3) | 78 f1 02 00 04 00 00 00 | 192888 | 4
(2,4) | 78 f1 02 00 05 00 00 00 | 192888 | 5
(3,1) | 79 f1 02 00 00 00 00 00 | 192889 | 0
(3,2) | 79 f1 02 00 01 00 00 00 | 192889 | 1
(3,3) | 79 f1 02 00 02 00 00 00 | 192889 | 2
(3,4) | 79 f1 02 00 03 00 00 00 | 192889 | 3
(4,1) | 79 f1 02 00 04 00 00 00 | 192889 | 4
(4,2) | 79 f1 02 00 05 00 00 00 | 192889 | 5
(4,3) | 7a f1 02 00 00 00 00 00 | 192890 | 0
(4,4) | 7a f1 02 00 01 00 00 00 | 192890 | 1
(5,1) | 7a f1 02 00 02 00 00 00 | 192890 | 2
(5,2) | 7a f1 02 00 03 00 00 00 | 192890 | 3
.
.
.
(12,3) | 7f f1 02 00 02 00 00 00 | 192895 | 2
(12,4) | 7f f1 02 00 03 00 00 00 | 192895 | 3
(13,1) | 7f f1 02 00 04 00 00 00 | 192895 | 4
(13,2) | 7f f1 02 00 05 00 00 00 | 192895 | 5
(13,3) | 80 f1 02 00 00 00 00 00 | 192896 | 0
(13,4) | 80 f1 02 00 01 00 00 00 | 192896 | 1
(14,1) | 80 f1 02 00 02 00 00 00 | 192896 | 2
(14,2) | 80 f1 02 00 03 00 00 00 | 192896 | 3
(14,3) | 80 f1 02 00 04 00 00 00 | 192896 | 4
(14,4) | 80 f1 02 00 05 00 00 00 | 192896 | 5
(60 rows)
Note that the chunk_ids coming from the index, the user table tuples and the toast itself match.
Use case example: a toast’s page is corrupted and I want to know which tuples from the user table are affected
Say the page 12 of the toast is corrupted, then we could get the affected chunk_id and chunk_seq from the toast index that way (by filtering on the ctid):
toasted=# select
page_items.ctid,
page_items.data,
('x'||regexp_replace(substr(page_items.data,1,11),'(\w\w) (\w\w) (\w\w) (\w\w)','\4\3\2\1'))::bit(32)::int as chunk_id,
('x'||regexp_replace(substr(page_items.data,13,23),'(\w\w) (\w\w) (\w\w) (\w\w)','\4\3\2\1'))::bit(32)::int as chunk_seq
FROM
generate_series(1, pg_relation_size('pg_toast.pg_toast_192881_index'::regclass::text) / 8192 - 1) blkno ,
bt_page_items('pg_toast.pg_toast_192881_index', blkno::int) as page_items where ctid::text like '(12,%';
ctid | data | chunk_id | chunk_seq
--------+-------------------------+----------+-----------
(12,1) | 7f f1 02 00 00 00 00 00 | 192895 | 0
(12,2) | 7f f1 02 00 01 00 00 00 | 192895 | 1
(12,3) | 7f f1 02 00 02 00 00 00 | 192895 | 2
(12,4) | 7f f1 02 00 03 00 00 00 | 192895 | 3
(4 rows)
And then look back at the user table tuples that way by filtering on the chunk_id:
toasted=# select
page_item_attrs.t_ctid,
page_item_attrs.t_attrs[2],
substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-7,4)::text,3) as substr_for_chunk_id,
('x'||regexp_replace(substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-7,4)::text,3),'(\w\w)(\w\w)(\w\w)(\w\w)','\4\3\2\1'))::bit(32)::int as chunk_id,
substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-3,4)::text,3) as substr_for_toast_relid,
('x'||regexp_replace(substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-3,4)::text,3),'(\w\w)(\w\w)(\w\w)(\w\w)','\4\3\2\1'))::bit(32)::int as toast_relid
FROM
generate_series(0, pg_relation_size('bdttab'::regclass::text) / 8192 - 1) blkno ,
heap_page_item_attrs(get_raw_page('bdttab', blkno::int), 'bdttab'::regclass) as page_item_attrs
where
substr(page_item_attrs.t_attrs[2]::text,3,2)='01' and ('x'||regexp_replace(substr(substr(page_item_attrs.t_attrs[2],octet_length(page_item_attrs.t_attrs[2])-7,4)::text,3),'(\w\w)(\w\w)(\w\w)(\w\w)','\4\3\2\1'))::bit(32)::int = 192895;
t_ctid | t_attrs | substr_for_chunk_id | chunk_id | substr_for_toast_relid | toast_relid
--------+----------------------------------------+---------------------+----------+------------------------+-------------
(0,9) | \x011214270000102700007ff1020074f10200 | 7ff10200 | 192895 | 74f10200 | 192884
(1 row)
so that we know that this tuple with ctid (0,9) is linked to the corrupted toast page.
Remarks
- t_attrs[2] is used in the query to retrieve the information from the user table. This is because the TOAST-able field (message) is the 2nd of the relation.
- substr(page_item_attrs.t_attrs[2]::text,3,2)=’01’ is used to filter the user table tuples information. This is because 0x01 is used as TOASTed string marker (see the slide).
Conclusion
Thanks to pageinspect we have been able to retrieve the chunk_id directly from the user table tuples. We also have been able to link the user table tuples to the toast pages by using user table tuples and toast index data (not querying the toast at all).